From Data to Information: A few basic concepts and their applications in the context of MAGDA project.
Agronomists, advisors and farmers are constantly juggling a vast amount of data to feed reasoning or models (digital or otherwise) and ultimately make educated decisions. To be perfectly honest, this isn’t unique to agriculture: a doctor, a civil engineer, a baker, a highwayman, they all do it too. But in this respect, agriculture knows how to distinguish itself:
• Working with living things
• Numerous hazards (biotic, abiotic)
• Machinery, sensors
• Strategy (crop rotation, medium- and long-term crop selection) and tactics (crop management, corrective actions)
One would also add that farmers get lots of advice from various sources but will be on their own, facing the consequences of their choices, but this is another story.
In agriculture, we must manipulate a wide variety of data: plant, disease or pest observations, weather and agrometeorological data, on-board sensor data, technical and economic data, etc. But at the risk of being disruptive, data is of no interest on its own. We need to know a certain number of contextual elements to be able to use it. This is metadata, or context, allows to turn data into information and later, knowledge.
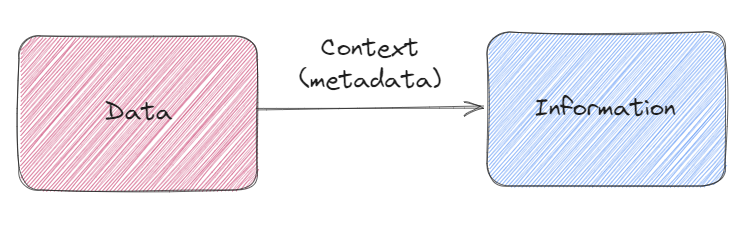
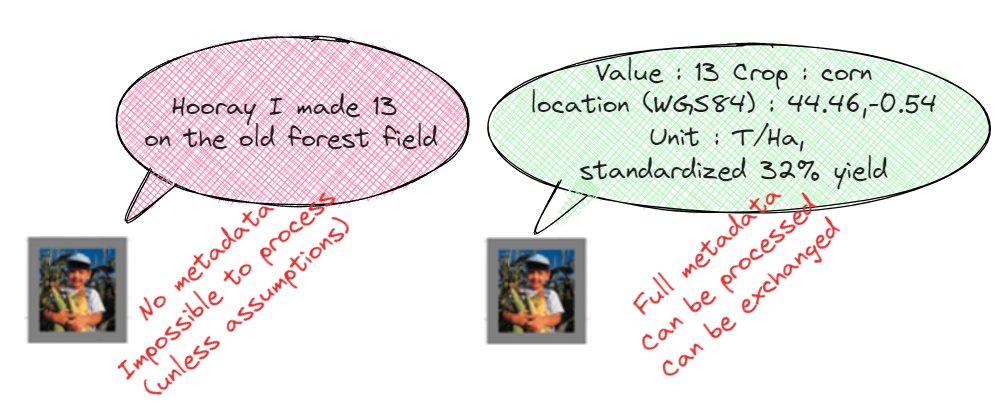
An example would be a yield information. The same data (13) can be either useless when provided without the proper metadata or exploitable.
The distinction between data and information is clear. It’s impossible to do anything with the data on the left, unless you make heavy and possibly dangerous assumptions. One could assume that the provided data is a raw yield which would cause problems if we assumed this for a mix of raw and standardized yields. The insight one would get from an analysis of this kind of data could be misleading in the end. The information on the right, on the other hand, follows a certain standard and provides us with everything we need to use it in a calculation or in a model, together with other data from different sources.
Surprisingly the metadata can be bulkier than the data itself. This can be a concern when it comes to storing and exchanging data. This is the same, or even worse for weather data: windspeed in m/s or km/h? Measurement at 10 m height or 1.5? Average or maximum on the acquisition timeframe? What is the expected precision of the measurement? And how far back is everything stored for statistical reference?
In MAGDA we have a specific concern about data and its metadata. MAGDA involves numerous data sources, from connected sensors, drones, and models from different partners in different countries. It’s not just a matter of storing this data which would be a challenge by itself, but some data sources feed other data sources (e.g. sensors feeding a model) and then feed another source all of which expect data to be in a specific format with specific qualities of accuracy, for example. We’d better have complete high-quality metadata in MAGDA!
To go further: We have seen that acquiring and storing metadata together with data is key. But what if we had not done this? It can be a challenge to add correct metadata to already acquired data (assumptions again!).
Let’s go back to the unusable data shown in the image (2) above: “Hooray I made 13 at the old forest field”. Algorithms have been developed to decode this kind of data, automatically adding metadata and turning it into usable information. A closer look at this message reveals several elements:
• “Hooray” seems to indicate good performance at least relative to what would be considered as a good yield in this specific location or for this specific year.
• There is also a picture where corn can be identified by image processing or artificial intelligence, suggesting that the numerical value is a corn yield in a common measurement unit.
• Based on these two pieces of information we can with a certain confidence determine if the yield is standardized or not.
• The “old forest field” is apparently a location information which sounds very generic and could designate thousands of locations on earth, but with additional context, such as the region or the city of the farmer, it can be converted to geo coordinates quite easily.
Poorly contextualized information such as our example of poor documentation or limited statements commonly found in social networks. Extracting useful information from a single variable is complicated because context is oftentimes lacking, contextual data from a timeline can help filling some of the gaps. In addition to the date of the message, there might also be information on the sender: accessible biographic data, a location, prior statements or publicly visible interests and subscriptions.
Back to MAGDA now. Our goal is to add value to properly contextualized data from sensors and models. We try to collect required metadata at the same time as we collect the core data itself. This is more efficient and simpler than trying to later add context to poorly structured data, but a challenge for our experts nonetheless with the sheer number of contextual variables and all their interrelations to be processed constantly.
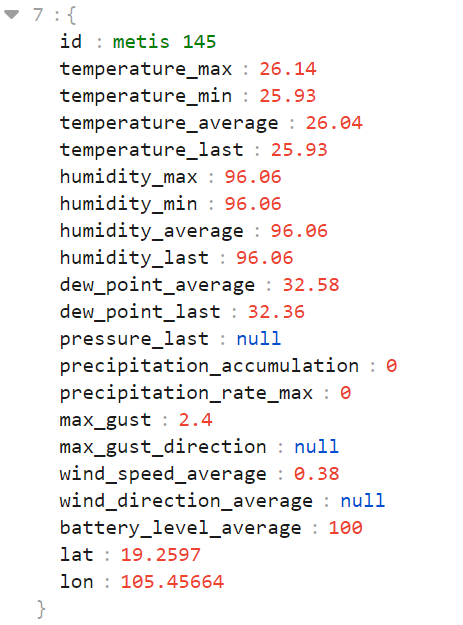
Variable overview of MAGDA data collection
Keywords
Metadata, Modelling, GNSS, agriculture, innovation, MAGDA, reflectometry, meteorology
Author: Julien Orensanz (CAP2020)


